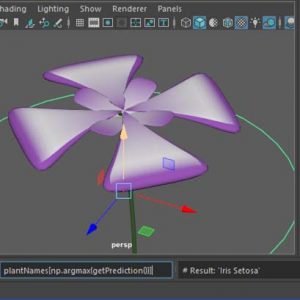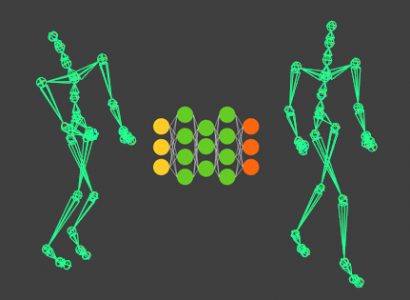
In short Neural Networks can learn patterns from data. That lets you program tasks that are easy for a person/expert to do but are hard for such people to explain how they’ve done it. Like, face recognition, for example. What good are they for 3D animation?
In 3D animation, there are many such tasks like animating or modeling stylized characters, classifying movement, rotoscoping hair against a noisy background, lighting a scene from an image reference and so on. These are all great tasks for a Neural Network, provided you have the right data.
In this article I’ll explain how Neural Networks work, in four steps:
What are Artificial Neurons and Neural Networks?
What can Neural Networks do for me?
Why are there different many different types of Neural Networks? Do I need to know them all?
This article goes over most of the basics in a high-level way. So, be warned you will see some oversimplifications. If you want to know how to train a Neural Network and use it in Maya, I’ve got you covered.
The Artificial Neuron and Neural Networks
Neural Networks are bio-inspired, hence the name. The smallest unit of a Neural Network is a neuron (aka. artificial neuron, or perception) and it looks like this:
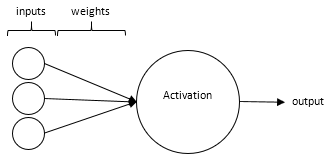
The artificial neuron may receive many inputs, which are just scalar values, and such values are filtered (multiplied) by weights (other scalar values). The sum of all filtered inputs will result in the neuron’s activation. The activation may be remapped by an ACTIVATION FUNCTION, as we’ll see later. Anyhow the resulting activation is the neuron’s output.
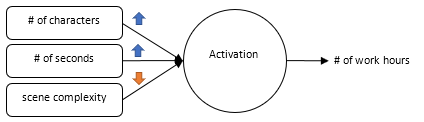
Here is a practical example. Say you want to model how long an artist takes to animate a scene. Your inputs might be the number of characters, the number of seconds, and the complexity of the scene. Each of these variables affects the artists’ performance in different ways. Hence, the filter values for each of them are different.
Let’s say after observing artists we conclude that the first two variables have a significant impact on the output, but the last one not so much. Weights for the number of characters and the number of seconds will be high, while the weight for scene complexity will be low. It’s easy to see how the sum of (inputs * weights) will impact the number of work hours in a way that matches the observations. The process of getting the correct weights is called LEARNING (I’ll talk more about it shortly).
But why would you use a network of neurons?
Let’s say you add more variables to the problem. You add a Boolean each for animators A, B and C, and other Booleans for each day of the week. Our initial observations will probably not hold true for every day of the week nor for every animator, making our problem linearly non-separable. Single neurons cannot deal with linearly non-separable problems. For these kinds of problems, we mesh neurons into a network.
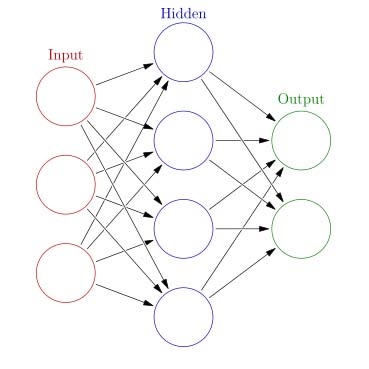
In the diagram, you can see that in a network the inputs activate intermediate neurons (HIDDEN LAYER), and the activation of these neurons, through a second set of filters, activates the OUTPUT LAYER. Thus, we separate the problem into little parts.
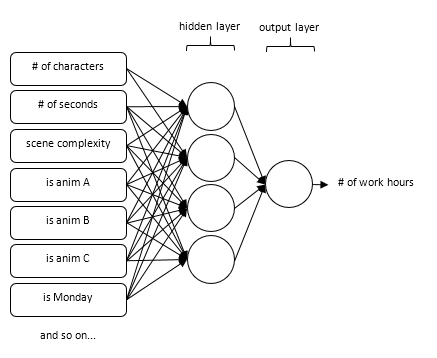
There is no limit for the number of neurons you can have in the hidden-layer, plus you can have more than one hidden layer. So, in theory, A NEURAL NETWORK CAN APPROXIMATE ANY FUNCTION! 😱
How do networks learn?
As we have seen in the first example, learning is all about getting the correct weights, so input values will activate the neurons that in turn will generate the expected outputs.
BACKPROPAGATION is the process of updating the weights based on the observed data. So, it assumes you have a database of observations. In our example, those would be the records of the ‘# of work ours’ of many animators and the characteristics of each job. Here is what backpropagation does with data:
- First, the algorithm assigns a random number to each weight.
- Using the dataset, it checks, for every given sample, how far and in which direction the networks predicted outputs differ from the known outputs; traversing the network all the way to the inputs.
- Then it updates the weights just a bit in the direction that would make the networks’ results closer to the actual outputs.
- Finally, it repeats steps 2 and 3 until results are good enough.
The distance to the correct results is calculated by the LOSS FUNCTION. The actual loss function may vary depending on the task and network structure. Loss functions must be differentiable so backpropagation can now in which direction it can move towards the correct results.
Each step of going through all samples in the data and updating the weights is called an EPOCH. The number of epochs needed to get the best results may vary a lot. One major factor in this variation is the size of the steps taken in each update. This parameter is the LEARNING RATE.
If you don’t have enough memory to fit all samples in memory, you should divide the data into MINI-BATCHES.
Neural Network applications
One can expect a network to do one of two things: 1) generate numbers, or 2) classify things.
When you use a network to generate numbers, like the ‘# of work ours’ in the previous example, it is said you are doing a REGRESSION. Classifications have no fancy names.
So, what’s the use of that?
Well, here are some ideas for classification nets in 3D animation, VFX, and games: classifying motions, classifying objects in images, classifying erroneous jobs in a render farm, classifying gestures of user input, and so on.
What about regressions? Well, you could generate color values for HDR probes based on reference images; create height maps from albedos; character poses from high-level parameters like speed and movement type, and so on.

Here is an example, from my thesis, where a classification network is used to learn motion types, and a regression network is used to learn motion phase.
The difference between these two types of networks (regression and classification nets) are the ACTIVATION FUNCTIONS used in the output layers. Regression networks use ‘linear’ outputs; classification networks use ‘sigmoid’ or ‘soft-max’ activations.
LINEAR activation means the neurons will be remapped linearly and will able to represent any number from minus to plus infinity.
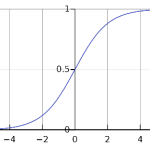
The SIGMOID function goes from zero to one, soft-clamping both ends. Hence it is great to represent Boolean values, like ‘is of category X.’
SOFT-MAX is used when you have more than one neuron in the output layer, and one of them should be classified as a winner. Values will be normalized so the sum of all activations will be one.
Why are there many network types?
In theory, the network structure showed in the last diagram can approximate any function. Given enough data, time, and neurons in the hidden layer. But you might not have all of these to spare.
Many different network architectures have emerged to address various tasks in different domains. Some designed for image classification (Convolutional Neural Networks), others for dealing with sequenced data (Recurrent Neural Networks), and so on.
We will talk about these particular cases and their applications in future articles. Until then, here are some resources you might find useful if you want to dig deeper into the theory and math of Neural Networks.